In this new series of blog posts, Jon Dainton will be breaking down the history of the internet, from inception to present day, and describing the basics, fundamentals and complexities of how the internet works.
When you browse for a website on the internet you can find what you want instantly by entering the name of your chosen website in the address bar of your browser. But how does your computer know where to find the website that you want?
If you’re just browsing the internet or sending emails you probably don’t need to know precisely what is going on in the background, but understanding how your computer finds the information you want can help you if you ever come across any problems.
The internet as we know it wasn’t designed, in the traditional sense, but has evolved over time. With this in mind, the best way of understanding how the internet works today is to look back at how it started, and show the problems early developers encountered and the solutions they came up with to overcome these obstacles.
In this series of articles, we will go into details on how the internet was born, and how it came to be what it is today.
A brief history of the internet
In the 50s and 60s, there were only a small number of computers around, and the first task IT developers faced was to get these computers to communicate with each other. This was achieved in the early 60s with a method called ‘packet switching’. We will explain packets and packet switching in a future article, and we do not need to know how it works right now, but it is interesting to note that packet switching is still the foundation of how the internet works today.
With packet switching, computers on the same network could communicate with each other. However, nothing was standardised and a computer on one network couldn’t communicate to one on a different network. In 1969, a new network was created to link research institutes and universities together. When it was first created on 29th November 1969 it connected the Stanford Research Institute with the University of California, Los Angeles. By December the University of Utah and the University of California, Santa Barbara were added to this network. This was named the ARPANET (Advanced Research Projects Agency Network) in 1972 and it started growing rapidly.
At this time, if you wanted to communicate to another computer you had to remember the network address of the computer you wanted to talk to. This was becoming impractical and a plan was needed to make remembering these addresses easier. Humans are good at remembering names, but not very good at remembering numbers. For instance, people remember me as Jon, but if I changed my name to 213.171.155.1 it is likely that I would receive fewer Christmas cards and voting would be problematic.
A new text file was introduced, called the ‘hosts’ file, that allowed users to assign easy-to-remember names to computer network addresses. This file is still in use today nearly 40 years later. On windows machines this can be found at C:\WINDOWS\system32\drivers\etc\hosts. The file can be opened using notepad, or any text editor.
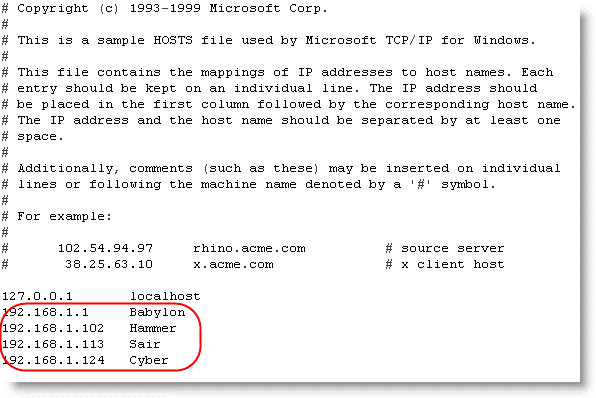
I use the hosts file at home to easily remember the computers on my network. I have four computers called Babylon, Sair, Cyber and Hammer (granted they are strange names, but there is method to my madness). Using the hosts file I can associate them with an IP address as shown above.
You may notice at the top of the list there is an entry for localhost on the IP 127.0.0.1, this is the IP address for your machine.
This enables me to just remember the computer names, rather than the full addresses. If I want to connect to ‘Sair’ for example, I can just type ‘Sair’ rather than remembering the address (192.168.1.113).
While the ARPANET was growing in popularity the problem with communicating with other networks was still causing issues. What was needed was a shared protocol that all computers could use to communicate with each other. With this protocol, all computers could use the same language and all computers, regardless of network, could talk to any others using the same protocol. The protocol that was designed evolved into TCP/IP (Transmission Control Protocol/Internet Protocol). We will explain TCP in more detail later, but first, let’s look at Internet Protocol (IP).
What is an IP address?
It’s unlikely that you’ve ever typed http://74.125.224.72/ into the address bar of your browser, but you may have visited this site on many occasions without realising it. 74.125.224.72 is the IP address for google.com. Unlike humans, computers use numbers – not names – to recognise each other on the internet. These numbers are used by the protocol used on the internet, hence the name Internet Protocol addresses (commonly shortened to ‘IP address’).
An IP address is a group of numbers that uniquely identifies a computer on the internet. IP addresses are groups of four numbers separated by a dot. This is known as IPv4. Humans have ten fingers, and it is largely due to this that we have the decimal (base 10) numbering system that we use today. However, computers were not designed with this handy counting system and so use binary (base 2) to complete all their calculations.
Numbers in the IP address can only go up as far as 255.255.255.255. This provides a theoretical 4,228 million (255*255*255*255) different IP addresses available on the internet, however many of these IP addresses are reserved and cannot be used. At the time of creation, it was thought that this number of IP addresses would be more we’d ever need. However, it was never imagined that the internet would ever be used to the extent it is today. In fact, we’ve almost run out of IPv4 addresses, and as such have evolved into IPv6, but more on that later.
The introduction of the hosts file and common protocols enabled the internet to grow further. Before long it became impractical to keep the addresses of every computer on the net in a text file on your computer. If someone wanted to join the net they would have to inform every computer already listed and hope that they would update their hosts file accordingly.
The next step was to have one central computer that would store this information. If you added a new record you only had to inform this central computer. Likewise to keep your records up to date you only needed to get the file from the central computer whenever you wanted to update.
This system worked well from 1973 to 1983, and then the number of people connected to the net made it impractical.
The hosts file was becoming too big, and the constant changes made to the file made downloading it every night a common occurrence. The solution found is the basis for how the internet works today, and was an elegant solution to a problem that had been perplexing engineers for some time. The solution was found in the use of domain names, and a concept known as DNS.
Learn more: What is a domain name?
